Chaos engineering in an Azure environment: Confident enough to try it?
 What could go wrong with your Azure environment?
What could go wrong with your Azure environment? Netflix gave the world two beautiful gifts: a media streaming platform for the general public and a wonderful monkey for the tech community. Enough has been said about the media streaming part, so let's play (or work) with the monkey now. When Netflix let the world know about Chaos Monkey, the tech community took a minute to stand and applaud. Since then, it has been a standard to unleash intentional chaos just to see how robust our tech stacks really are.
For those who know Chaos Monkey by different names, it all started when Netflix developed a tool that intentionally wreaks havoc in its systems and watches where the impacts are. A resilient infrastructure should not let the customers be affected, so Chaos Monkey exposes the weak points. The term chaos engineering became more prevalent, encouraging lots of organizations to use it to smoke out bugs that were usually not found for even decades.
That brings us to the primary question: Why should you even consider chaos engineering in an Azure environment? The cloud is a brilliantly built, complex product. A typical enterprise uses multiple Azure products for its applications and services. These services are all loosely connected to each other but very much dependent. An outage or performance degradation in one service can transfer to other services faster than you expect. Availability zone failures are also a big factor to consider when trying to make your infrastructure resilient. But again, why chaos engineering in an Azure environment specifically?
Cloud services host different processes in different services split into packages. The chance of a failure going unnoticed is greater on a cloud platform than in an on-premises setup because you have data, processes, and applications in silos. Azure is our example for today, but the chaos engineering scenario holds true for all other public cloud service providers.
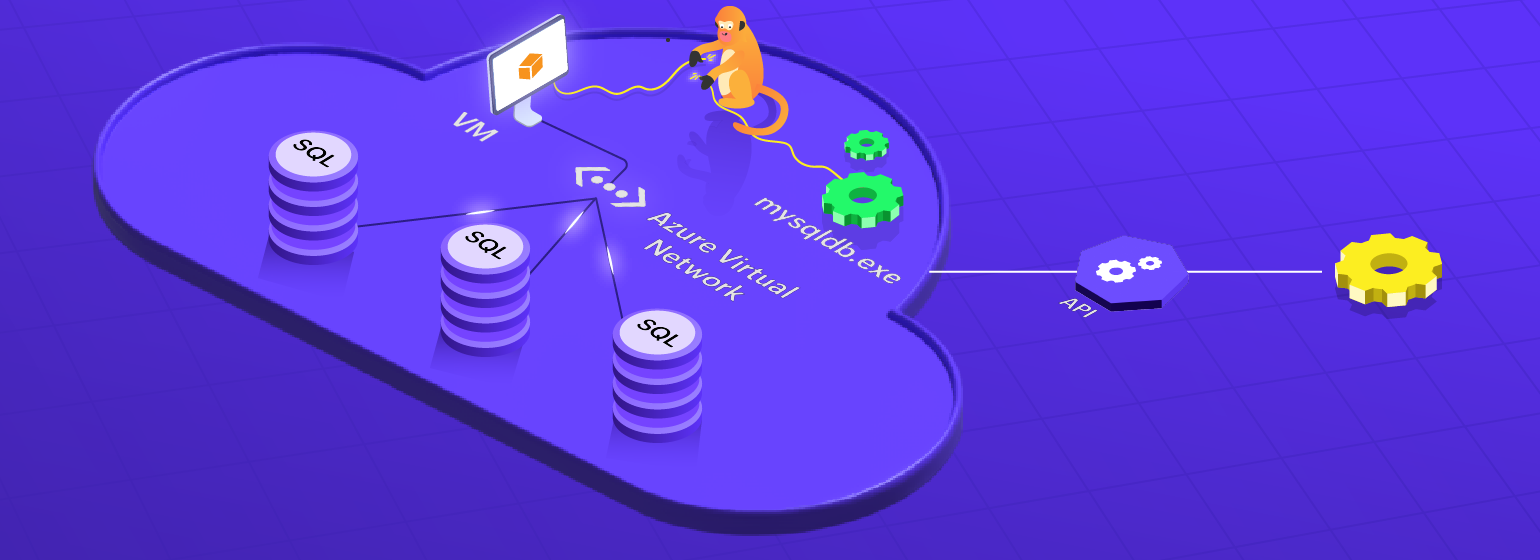
But the cloud is robust, isn't it? Robust, yes. Infallible, no. Let's look at a small-scale example. An application relies on databases hosted on Azure virtual machines (VMs). These VMs are connected using Azure Virtual Network. The usual DDoS attacks are easily handled by Azure Virtual Network. Yay! Robust? Yes.
But what if a tiny little chaos monkey kills a VM? What will be the answers to the following questions?
- Has the VM restarted?
- Are the databases connected to the VM fine?
- Are the databases dependent on the VM experiencing high latency?
- Were any customers affected because the VM was shut down?
- For how long were the customers affected?
Those are the questions that come within the first 10 seconds of imagining the situation. But in reality, when this scenario happens in production, smoke comes out of a substantial amount of other dependent services as well. Infallible? No.
What if there is chaos, but you don't know it? You do not want to be in a position where there is data loss or something is broken, but nobody is aware of it until an angry customer drops a two-page-long email threatening to move to your competitor. In terms of the example above, the VM is running perfectly fine, but what if mysqldb.exe has not started even after restarting the VM?
As much as it sounds scary (and exciting), chaos engineering prepares you for the worst. Teams worldwide deploy chaos monkeys at least in their test environments (if they feel brave on the day, in their production environments as well) to see the weakest links and deploy countermeasures. If you feel ready to start chaos (engineering), head right away to Azure Chaos Studio, where you will see instructions on how to use Azure's own tool to try chaos engineering.
How does Site24x7 fit here?
Be it a fully contained chaos engineering scenario or an unplanned outage, Site24x7 sends alerts to the right people before your business gets hurt. To put this into the scenario above:
- When the VM shuts down:
- Site24x7 sends a down alert to the sysadmin.
- IT Automation jumps into action and tries to restart the VM.
- The Azure Virtual Network monitoring integration sends a down alert stating that there are lots of failed pings to the VM.
- Site24x7 sends alerts stating that your databases are facing performance degradation through either the Azure Database for MySQL integration or the MySQL database monitoring integration.
- Once the VM has been restarted:
- Site24x7 sends you a notification that the VM is back online.
- Site24x7 sends you an alert that the service mysqldb.exe is down.
This gives you an accurate map of all the smoke points, giving you ample time to deploy temporary mitigation measures while you work on permanent fixes. Again, this is a very small-scale representation of what a chaos monkey can do. The bottom line is that you should not wait until an outage to secure your Azure setup.
Site24x7 is an enterprise-grade observability solution for DevOps and ITOps. Our Azure monitoring solution alerted customers to close to 1.4 million outages in 2023. Site24x7 supports more than 100 Azure service types for monitoring so you can view the health of your entire IT infrastructure in one place.
Organizations choose Site24x7's Azure monitoring because the observability layer we provide is fast, reliable, robust, and scalable. But we don't want you to just take our word for that. Try Site24x7's Azure monitoring for free and secure your tech stack.
Comments (0)