Resolve issues faster in your containerized environment by monitoring Kubernetes with Site24x7.
Every developer has faced the need to quickly and effectively troubleshoot their application. This can be a challenge without the necessary knowledge and appropriate tools, especially in a Kubernetes environment.
The most frequent questions developers will ask themselves are:
Understanding container logging basics within Docker and Kubernetes will provide the answers to the above questions and enable you to troubleshoot your application, run logs analyses, and promptly find and fix problems.
This article will show you how to run container and containerized logging and cover how and where logs are stored. In addition, it will provide an in-depth comparison of different architecture logging techniques.
stdout and stderr streamsBefore exploring different search and viewing options for logs, it is vital to discuss the data streams that make it possible to work with logs data in the first place. Each running Unix process works with the basic data streams stdin (standard input), stdout (standard output), and stderr (standard error).
stdin |
The stream responsible for working with input commands |
stdout |
The stream into which programs write their outputs |
stderr |
The stream into which programs write error outputs |
An example of stdin can be any command you type in the terminal, such as:
 Fig. 1: This command will open the
Fig. 1: This command will open the logs folder
Meanwhile, stdout can be any command that makes it possible to show a list of files within the folder.
 Fig. 2: After execution, the terminal returns the result of the command through
Fig. 2: After execution, the terminal returns the result of the command through stdout
Finally, stderr can be any error that occurs during command execution.
 Fig. 3: The error occurred due to a command that does not exist in the system. The error was returned by stderr
Fig. 3: The error occurred due to a command that does not exist in the system. The error was returned by stderr
To determine whether the last command was executed successfully, examine the code returned after executing the command, which you can view by executing echo $?
In the case of stderr, the result will always be code > 0, while with stdout, the code equals 0. What does this tell us?
== 0 |
Successful command execution |
> 0 |
“Non-zero error code” highlighting command error |
It is also important to consider that each data stream has its own system number identifier with the following correspondence:
stdin |
0 |
stdout |
1 |
stderr |
2 |
The stream output location can easily be changed by defining the corresponding number. For example, to stream stderr to the errors.log file, write the following command:
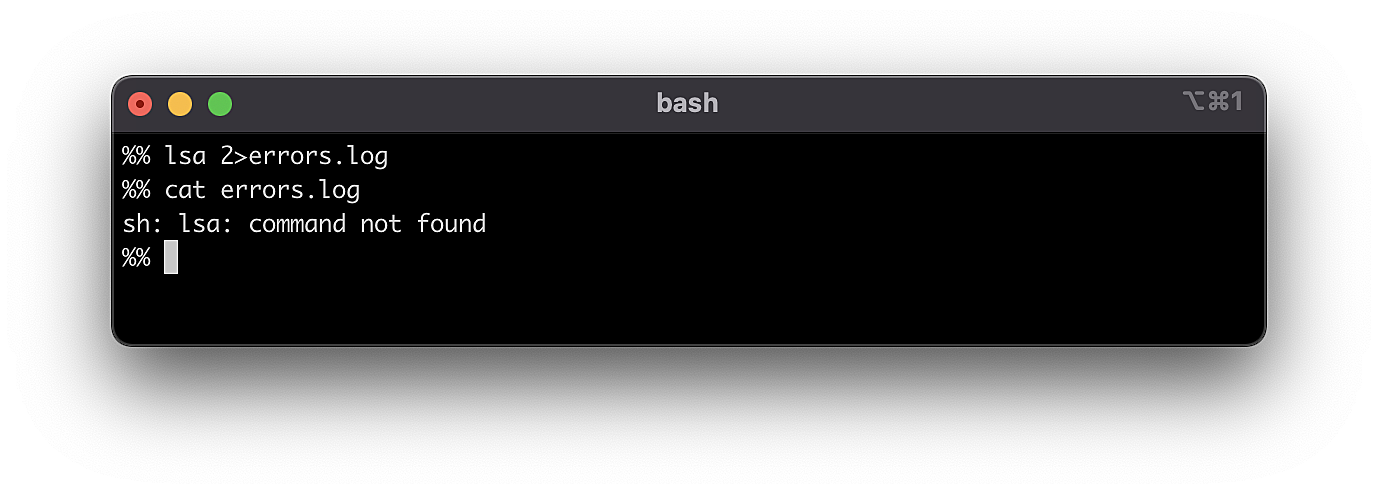 Fig. 4: Incorrect command execution
Fig. 4: Incorrect command execution
Since lsa is an incorrect command, the terminal can’t run it correctly. Accordingly, the error is returned through a stderr stream. The stderr system code is 2, so we can route our stream data to the errors.log file.
Armed with just a basic knowledge about data streams, you will be able to understand how the logging system works in Docker and Kubernetes.
Before any discussion directly about logs, a quick refresher about Docker and Docker containers is in order.
stdout and stderr data streams.By default, Docker uses the JSON logging driver. It allows developers to collect information in the standard JSON format and collect information from stdout as well as stderr data streams.
To find the logs file related to your Docker container, you must first find the id of the container. This can be done by running docker ps—this command will display a list of all currently running containers in a table format.
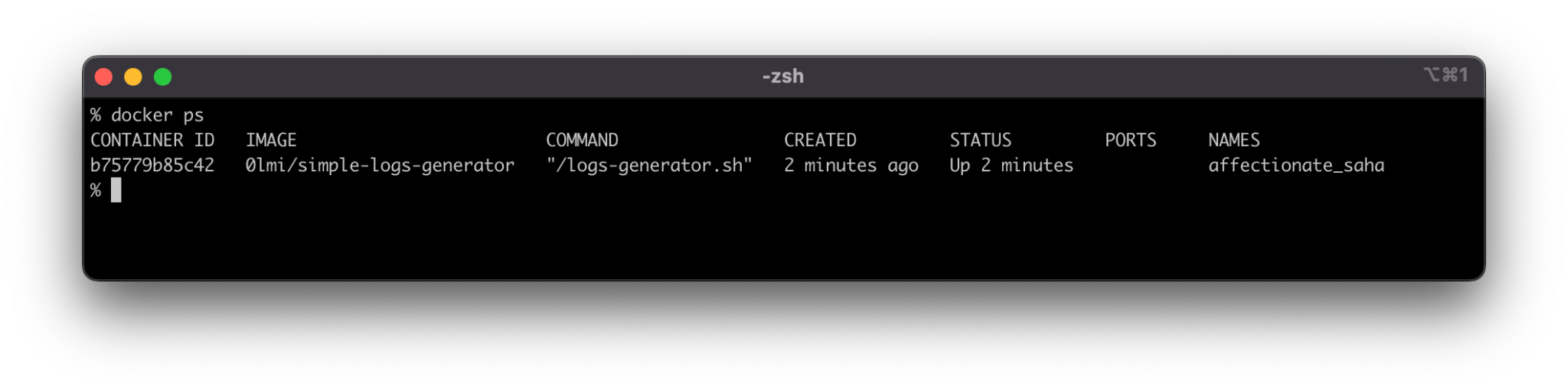 Fig. 5: List of running Docker containers
Fig. 5: List of running Docker containers
For this example, we have used a Docker image pulled from Dockerhub. It generates AWS logs.
In the above example, the id of the container is b75779b85c42. Using this id, we can execute the command docker logs b75779b85c42 and get the latest container logs.
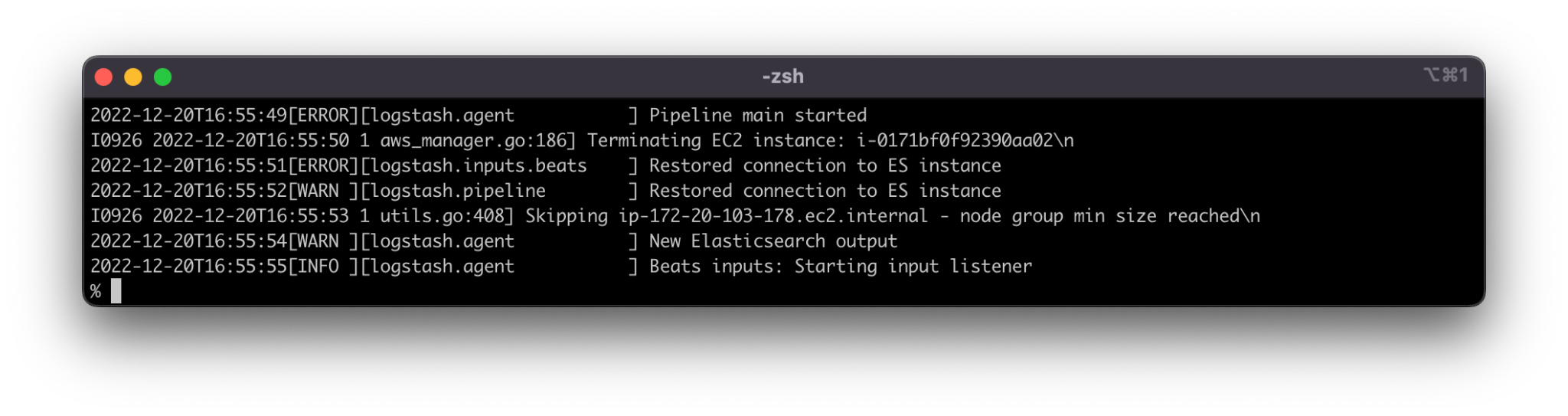 Fig. 6: The results after executing docker logs b75779b85c42
Fig. 6: The results after executing docker logs b75779b85c42
Using the built-in logging driver, we can easily view up-to-date container logs. An interesting Docker feature when working with logs is that we can specify a custom logging driver and route all logs into the centralized environment (as described further down in this article).
Now with an understanding of how the logging driver works, it’s time to examine the implementation for Kubernetes pods.
A Kubernetes pod is the smallest computing unit in the Kubernetes ecosystem. It allows developers to use several Docker containers simultaneously and share the network interface and others within the unit.
Kubernetes and Docker require a similar approach when collecting logs. In Kubernetes, kubelet and Kubernetes API is used for log collection, which allows developers to monitor the state of resources and provides access to logs using data obtained from the stdout and stderr data streams of the containers.
Kubernetes allows for multiple different logging approaches. This article will cover one that is widely used—containerized logging.
The main goal of this approach is to collect logs from containers using kubelet and Kubernetes API; accordingly, all resource logs are stored in the worker nodes of the Kubernetes cluster.
It’s worth noting that the main data sources for the logs are data streams, such as stdout and stderr.
The below example uses simple-logs-generator, now as a pod in the Kubernetes cluster. First, create a pod manifest with the simple-logs-generator container:
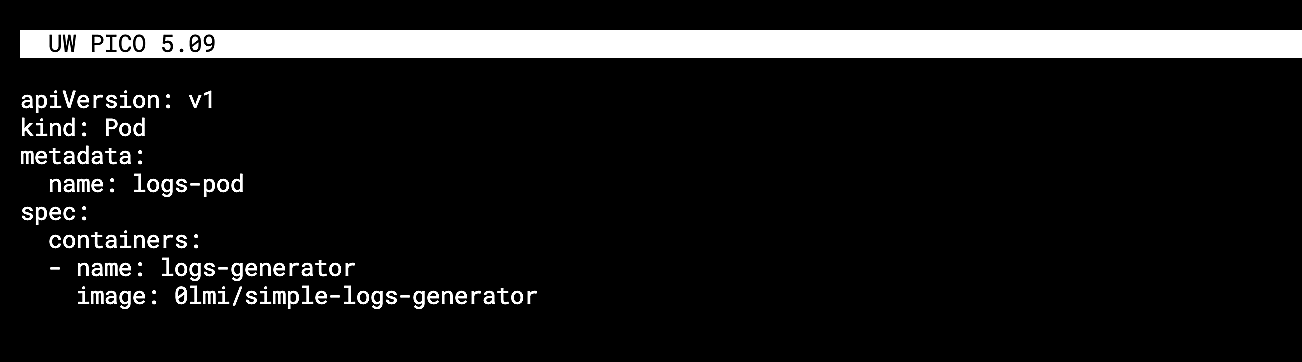 Fig. 7:
Fig. 7: logs.yaml manifest
Create a logs.yaml file and define a spec with the image name and location.
Now run the kubectl apply -f logs.yaml command to apply the logs.yaml manifest and create a new pod. After applying changes, check the status of the pod using the command kubectl get pod logs-pod in the terminal. The command should return information about the pod status.
Now it's time to look at the pod logs. kubectl provides the command for this:
kubectl logs logs-pod
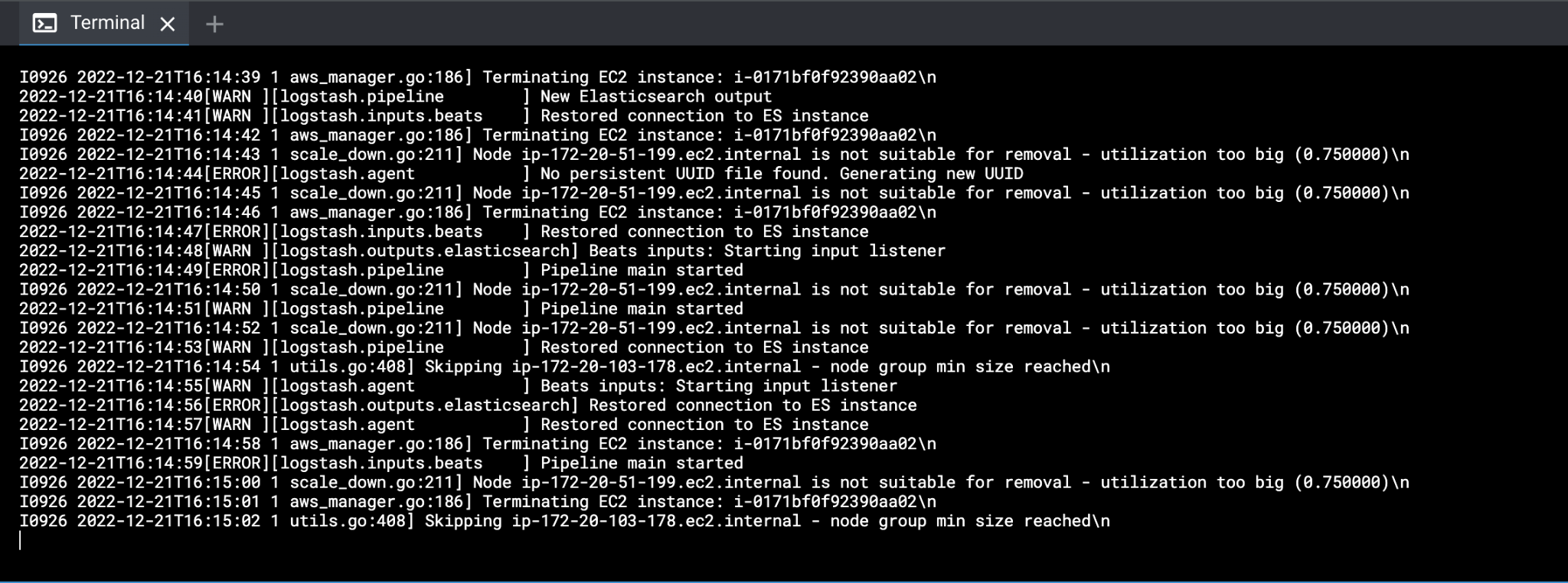 Fig. 8: The results of running
Fig. 8: The results of running kubectl logs logs-pod
It is also important to consider that the possibilities offered by kubectl logs do not end at viewing single pod logs. Since we already know that a pod can contain several containers, we can start the aggregation of logs from several containers at the same time, using the argument --all-containers=true.
By default, the kubectl logs command will return only a snapshot of the container’s latest logs. Therefore, to get a stream of logs in real time, consider using the -f or -follow parameter, which will allow you to start viewing pod logs in stream mode.
If the pod stops working and you need access to previous logs to troubleshoot and resolve any issues, you can use the kubectl logs logs-pod --previous command.
Having several pods doesn’t necessarily make viewing logs and troubleshooting the application more of a challenge—running several kubectl logs and identifying the pod is fairly simple and doesn’t require any extra knowledge.
But what if there are dozens of pods, deployments, and other workload resources in different namespaces? What if the goal is to run logs analysis in batches with the help of additional metadata?
Centralizer logging is the answer, as its core feature is the aggregation of logs from all available resources due to ready-to-run stacks such as EFK and ELK and the use of DeamonSet.
DeamonSet is a Kubernetes workload resource. As a key feature, it can be deployed to each Kubernetes worker node. In addition, it guarantees that as worker nodes are added to the cluster, pods are added to them, which then provides access to all logs available in file systems.
EFK (short for Elasticsearch + Fluentd + Kibana) is a ready-to-run stack that allows developers to collect, analyze, and quickly access Kubernetes workload resource logs.
ELK (Elasticsearch + LogStash + Kibana) is an option similar to EFK, but it uses LogStash as its main logs collector.
Elasticsearch and Kibana both act as the source for centralized logs and allow you to run powerful data analysis and run complex search queries.
Fluentd is similar to LogStash, but it offers broader capabilities like easy-to-setup plugins and filters. One of its most powerful features is that it supports logs data transfer to Elasticsearch.
Fluentd allows developers to collect logs from all available workloads within the Kubernetes cluster and stream them directly to Elasticsearch. It’s important to note that all data collected by the Fluentd collector is in JSON format. The wide range of attributes help with running complex queries within the database and finding information.
For our first example, we will implement the EFK stack. Start by installing Elastic Cloud on Kubernetes (ECK) and Kibana. The setup involves several steps:
To set up CRDs, run the following command:
kubectl create -f
https://download.elastic.co/downloads/eck/2.5.0/crds.yaml
This will install the appropriate CRDs that will make it possible to create Elasticsearch resources.
Next, install Elasticsearch Operator:
kubectl apply -f
https://download.elastic.co/downloads/eck/2.5.0/operator.yaml
Check if it works by running the following command:
kubectl create -f
kubectl -n elastic-system logs -f statefulset.apps/elastic-operator
Now create a new Elasticsearch cluster. For this, you’ll need to create a Kubernetes manifest file with the name elastic-cluster.yaml and add the below instructions:
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: quickstart
spec:
version: 8.5.3
http:
tls:
selfSignedCertificate:
disabled: true
nodeSets:
- name: default
count: 1
config:
node.store.allow_mmap: false
The manifest contains information about the resource we plan to create: The resource type is defined as Elasticsearch and its name as quickstart. It will be placed in the default namespace (for lack of a more explicit definition).
In addition, the version is specified as Elasticsearch 8.5.3, while the number of Elasticsearch nodes equals 1. Memory mapping is disabled (this option should be removed from config for production deployment), and so is SSL verification for local development (as it’s preferable to set SSL up for production deployment).
Next, install Kibana. The process is similar: Create a Kubernetes manifest file (kibana.yaml) and add the below instructions.
apiVersion: kibana.k8s.elastic.co/v1
kind: Kibana
metadata:
name: quickstart
spec:
version: 8.5.3
count: 1
elasticsearchRef:
name: quickstart
The manifest describes the resource type, the name quickstart, the version, and a reference to the Elasticsearch resource. Kibana must be available in the default namespace, as it’s not set explicitly. After running the kubectl apply command, Kibana should start with access to it within the web interface.
To get access to Kibana, execute the next command:
kubectl port-forward service/quickstart-kb-http 5601
It will run port forwarding and map your local port to a remote one. Now you can open localhost:5601 and log in to Kibana using the default username and password.
| Username | elastic |
| Password | To obtain the default password, run the command kubectl get secret quickstart-es-elastic-user -o=jsonpath='{.data.elastic}' | base64 --decode; echo |
To complete the final step of installing Fluentd, first set up DeamonSet using the following command:
kubectl apply -f
https://raw.githubusercontent.com/fluent/fluentd-kubernetes-daemonset/master/fluentd-daemonset-elasticsearch-rbac.yaml
Make sure to update the variables responsible for access to the Elasticsearch cluster in the Fluentd configuration—otherwise the logs will not get into the Elasticsearch.
FLUENT_ELASTICSEARCH_HOST |
your_elasticsearch_host |
|---|---|
FLUENT_ELASTICSEARCH_SCHEME |
http |
FLUENT_ELASTICSEARCH_SSL_VERIFY |
false |
FLUENT_ELASTICSEARCH_USER |
elastic |
FLUENT_ELASTICSEARCH_PASSWORD |
your_elasticsearch_password |
Previously, we’ve created a log pod. Now, Fluentd should automatically transport all pod logs to Elasticsearch, allowing us to view and query them within Kibana.
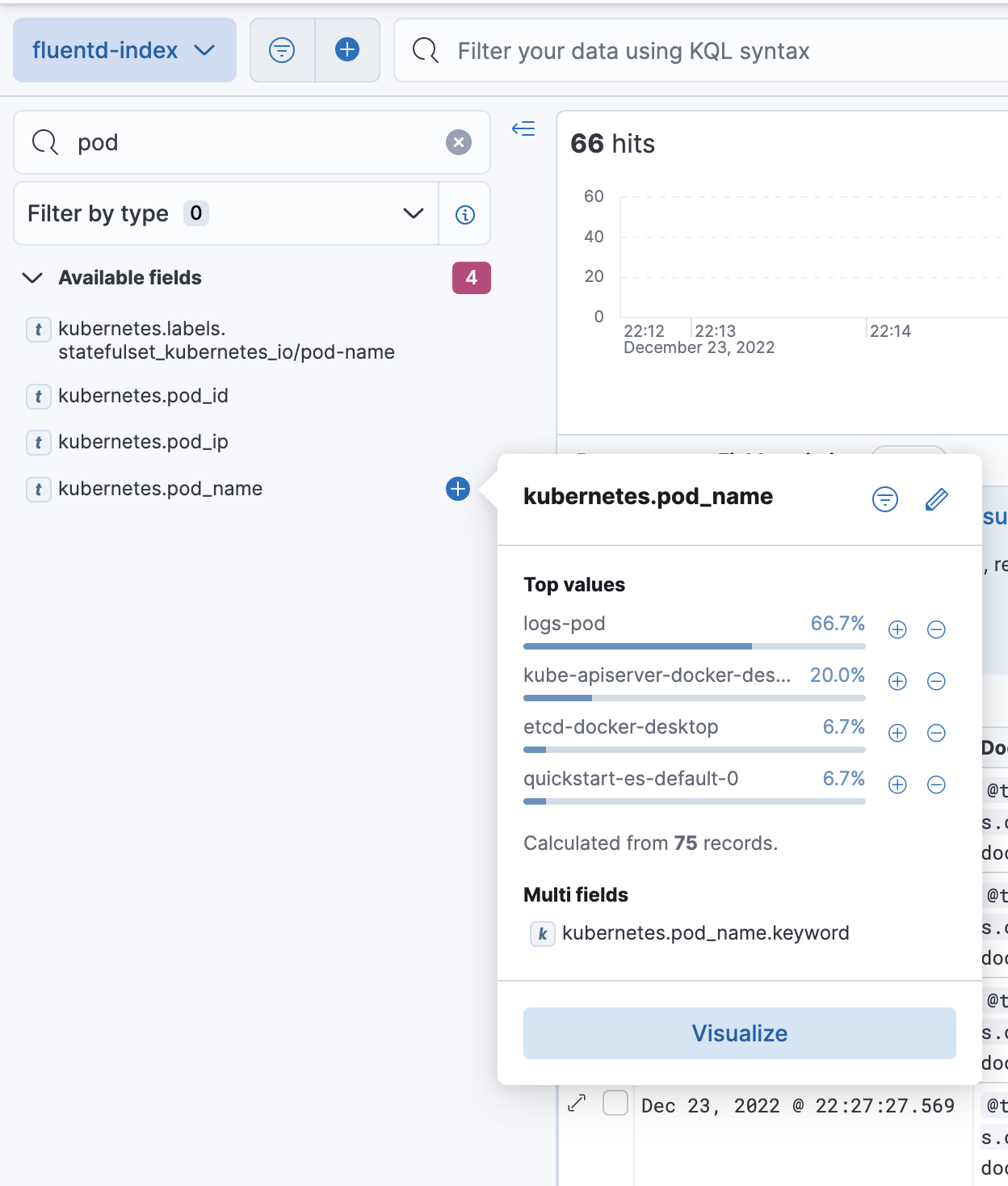 Fig. 9: In fluentd-index, we can search by the pod_name property and select logs-pod to start log analysis
Fig. 9: In fluentd-index, we can search by the pod_name property and select logs-pod to start log analysis
To find log records with the property pod_name: logs-pod and the utilization too big text property, write the KQL query log: "utilization too big"
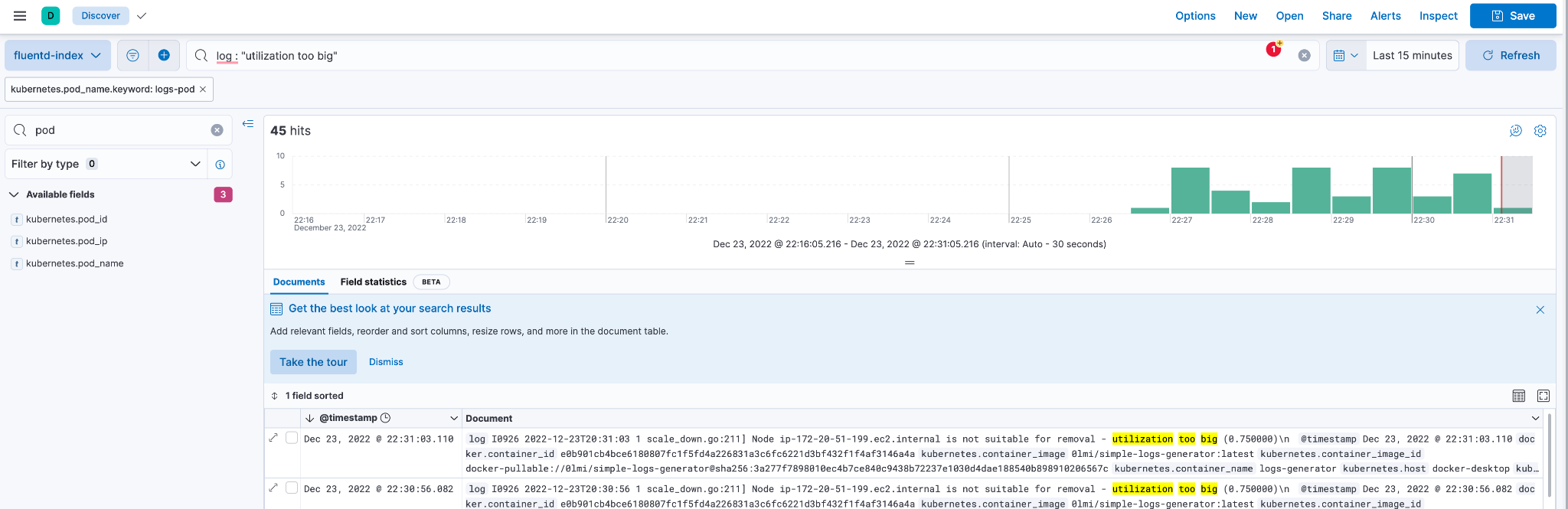 Fig. 10: Result for query
Fig. 10: Result for query log : "utilization too big"
The query returns 45 matches. We can use additional properties to run any sort of complex query.
The possibilities that Fluentd provides do not end here: There are different filters, plugins, and parsers available, as detailed in official Fluentd documentation.
Containerized logging is a decent solution for clusters with a small number of workload resources, where there is no need to analyze and search for information within a massive amount of logs data. It also offers one of the easiest ways to debug resources, as it does not require additional software.
The main disadvantage of containerized logging is that it has limited capabilities in multiple areas, especially compared to Fluentd:a lack of long-term log history, no data analysis, and the fact that it potentially requires large amounts of manual work.
Centralized logging extends the possibilities in analyzing and monitoring Kubernetes workload resources. There is no need to manually review resource logs, as all information is stored in the Elasticsearch database. Centralized logging allows developers to automatically collect logs from all existing and new worker nodes and transport all logs data to Elasticsearch. With Kibana, you can run a search, analyze and visualize data, use Kibana plugins, data tables, and dashboards.
One of the drawbacks of centralized logging is that it necessitates the installation and maintenance of an additional Elasticsearch and Kibana stack. It is also worth considering that this stack needs a lot of resources: Elasticsearch at least 2 GB of RAM, and Kibana 1 GB. Fluentd, meanwhile, demands that developers understand the intricacies of configuring various types of plugins and filters.
You can bypass the installation and maintenance process with a holistic log management system like Site24x7's Applogs, which eliminates the need for Elasticsearch, Kibana, and FluentD stack installation. It removes complexities by directing all the Kubernetes logs into a centralized log portal.
Choosing a logging method requires careful consideration of your system. If your infrastructure doesn’t involve deep analysis of logs data or a large number of workload resources, and you’re managing well with current system debugging, switching to centralized logging is not advised.
If you have many resources that are regularly analyzed and you require the ability to monitor your infrastructure's activity in real time, implementing centralized logging can provide significant advantages to your system.
Site24x7 AppLogs provides a centralized log management solution that automatically collects, parses, and indexes logs from all your Kubernetes pods, nodes, and the control plane. This eliminates the overhead of maintaining an ELK stack. Site24x7 supports both custom (static) thresholds and dynamic thresholds (AI-based anomaly detection) for log alerts.
Yes, Site24x7 allows you to create custom log alerts that trigger when specific error messages, exceptions, or patterns appear in your container logs. You can configure alerts for specific log patterns to proactively monitor application health.
Yes, Site24x7 seamlessly correlates pod and node performance metrics with their respective logs. This helps you quickly troubleshoot application issues by analyzing log patterns alongside performance data.
